Overview
Compact Blockリレー(BIP152)は新しいブロックをフルノードに伝播する際に使われる帯域幅を減らす方法です。
概要
フルノードが既に同じmempoolの内容の多くを共有している場合、シンプルな手法を使って、新しいブロックをフルノードに伝播するのに必要な帯域幅を大幅に削減することができます。ピアはCompact Blockの「スケッチ」を受信ピアに送信します。このスケッチには以下の情報が含まれています:
- 新しいブロックの80バイトのヘッダ
- サービス拒否(DoS)攻撃を防ぐために設計された短縮トランザクション識別子(txid)
- 送信側のピアが受信側のピアがまだ持っていないと予測するいくつかの完全なトランザクション
受信側のピアは受信した情報と既にmempoolにあるトランザクションを使ってブロック全体の再構築を試みます。それでも足りないトランザクションがある場合、送信側ピアにそれらを要求します。
このアプローチの利点は、最良のケースでは最初にブロードキャストされた際にトランザクションを一度だけ送信すれば良い点で、これにより全体的な帯域幅が大幅に削減されます。
さらに、Compact Blockリレーの提案では、受信側のノードがそのいくつかのピアに最初に許可を要求することなく新しいブロックを直接送信するよう要求する第2の動作モード(高帯域幅モードと呼ばれる)も提供されています。このモードは(2つのピアが同じブロックを同時に送信しようとするため)帯域幅が増加しますが、高帯域幅の接続でブロックが到着するのにかかる時間(レイテンシー)をさらに短縮します。
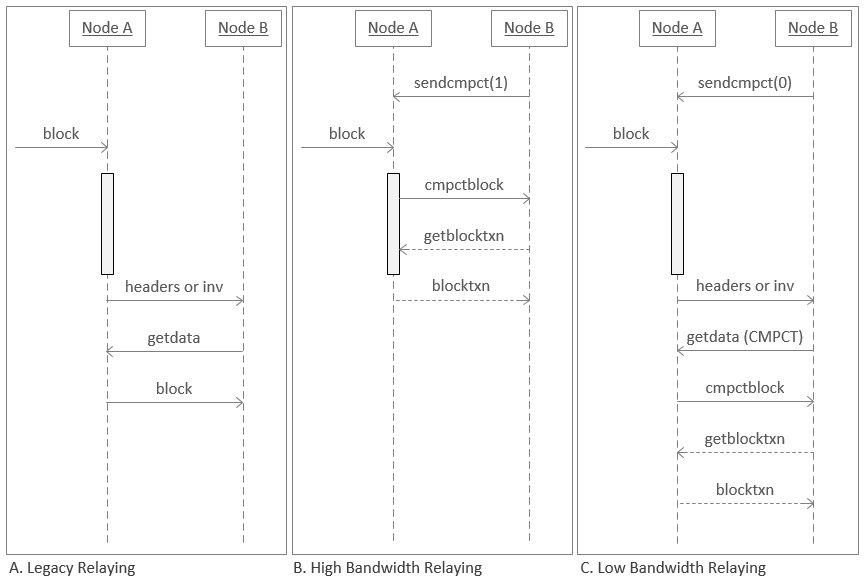
以下の図はノードが現在ブロックを送信する方法をCompact Blockリレーの2つの動作モードと比較して示しています。ノードAのタイムラインのグレーのボックスは、検証の実行期間を表します。
-
従来のリレーでは、ノードAによってブロックが検証され(グレーのバー)、その後ノードAはブロックを送信する許可を要求する
invメッセージをノードBに送信します。ノードBがブロックについて(getdata)要求で応答し、ノードAはそれを送信します。 -
高帯域幅リレーでは、ノードBは
sendcmpt(1)(send compact)を使ってノードAにブロックをできるだけ早く受信したいことを伝えます。新しいブロックが到着すると、ノードAはいくつかの基本的な検証(ブロックヘッダの検証など)を実行してから、ヘッダ、短縮txidおよび予測される不足トランザクション(前述)をノードBに自動的に送信し始めます。ノードBはブロックの再構築を試み、欠落しているトランザクションがあればノードAに要求 (getblocktxn)し、ノードAはそれを送信します (blocktxn)。バックグラウンドでは、両方のノードはブロックの完全な検証を完了してからブロックをローカルのブロックチェーンのコピーに追加し、これまでと同じフルノードのセキュリティを維持します。 -
低帯域幅リレーでは、ノードBは
sendcmpt(0)を使ってノードAにできるだけ帯域幅の使用を最小限に抑えたいことを伝えます。新しいブロックが到着すると、ノードAはそれを完全に検証します(そのため無効なブロックはリレーされません)。その後、ノードBにそのブロックが必要かどうか問い合わせます (inv)。これによりノードBが既にそのブロックを別のピアから受信している場合、再度ブロックをダウンロードするのを回避できます。ノードBはブロックを必要としている場合、それをコンパクトモードで要求し(getdata(CMPCT))、ノードAはヘッダ、短縮txidおよび予測される不足トランザクションを送信します。ノードBはブロックの再構築を試み、欠落しているトランザクションがあればノードAに要求し、ノードAはそれを送信します。その後ノードBはブロックを通常通り完全に検証します。
このための役立つベンチマークは?
受信ノードは9KBのブロックスケッチと受信ノードのmempoolにないブロック内のトランザクションのオーバーヘッドで、平均1MBの完全なブロックアナウンスを再構築できます。最大のブロックスケッチは20KBちょっとです。
「高帯域幅」モードでノードに最大6つのトランザクションを事前にもたせた状態でライブ実験を実行すると、不足したトランザクションを要求せずに90%を超えるブロックがすぐに伝播することが期待できます。コインベース以外のトランザクションを事前にセットしていないくても60%以上のブロックがすぐに伝播し、残りは完全な追加のネットワークラウンドトリップを必要とすることが分かります。
ウォームアップノードのmempoolとブロックの違いが6トランザクションを超えることはほとんどないので、これはCompact Blockリレーが必要なピーク帯域幅の大幅な削減を達成することを意味します。
すぐに転送されるよう予想される不足トランザクションはどうやって選択しますか?
最初の実装で見直す必要があるものの数を減らすため、コインベーストランザクションのみが先行して送信されます。
ただし、説明した実験では、送信側ノードは単純な式を使って送信するトランザクションを選択しました。ノードAがブロックを受信すると、どのトランザクションがブロック内にあり、mempool内にないか確認します。それらはそのピアが持っていないと予測したトランザクションでした。推論は(追加情報なしで)あなたが持っていなかったトランザクションは、おそらくあなたのピアが持っていないトランザクションでもあるからです。この基本的なヒューリスティックを使用すると、大幅な改善が見られ、最も単純な解決策が多くの場合最適であることを示しています。
Fast Relay Networkはこれをどう考慮しますか?
Fast Relay Network (FRN)は以下の2つのピースで構成されています:
-
現在Fast Relay Networkにあるノードのキュレーションセット
-
Fast Block Relay Protocol (FBRP)
FRNのキュレーションノードのセットは、最優先事項として世界中で最小限の中継が行われるよう慎重に選択されています。これらのノードで障害が起きると、無駄になるハッシュパワーが大幅に増加し、マイニングがさらに集中化される可能性があります。現在のマイニングハッシュパワーの大多数は、このネットワークに接続しています。
オリジナルのFBRPは、参加ノードがブロック情報をお互いに通信する方法です。ノードはお互いにどのトランザクションを送信したかを追跡し、この知識に基づいてブロックの差分を中継します。このプロトコルは新しいブロックの1対1のサーバ − クライアント通信にほぼ最適です。最近ではRN-NextGenerationという名前のUDPおよび前方誤り訂正(FEC)をベースにしたプロトコルが、マイナーによるテストや使用のために配備されています。しかし、これらのプロトコルは、よく接続されていないリレー・トポロジーを必要とし、一般的なP2Pネットワークよりも脆弱です。Compact Blockを使用したプロトコルレベルでの改善は、キュレーションされたノードネットワークと一般的なP2Pネットワークとの間の性能差を縮小します。P2Pネットワークの堅牢性の向上とブロック伝播速度の向上は、今後のネットワークの発展に重要な役割を果たします。
これはBitcoinをスケールさせますか?
この機能は、ノードのピークブロック帯域幅を節約し、エンドユーザーのインターネットエクスペリエンスを低下させる可能性がある帯域幅のスパイクを減らすことを目的としています。ただし、次のビデオで説明されているように、マイニングの集中化の圧力の大部分の原因はブロック伝播の遅延にあります。Compact Blockバージョン1は主にこの問題を解決するようには設計されたものではありません。
https://www.youtube.com/embed/Y6kibPzbrIc
低レイテンシーまたはより堅牢なソリューションが開発されるまで、マイナーはFast Relay Networkを使用し続けることが予想されます。しかしながら、ベースのP2Pプロトコルの改善は、FRNの障害が発生した場合の堅牢性を増し、おそらくプライベート中継ネットワークの利点を減少させ、それらを実行する価値をなくすでしょう。
さらに、最初のバージョンのCompact Blockを使用して実施された実験および収集されたデータは、今後のFRNとの競争力向上を期待した改良の設計に役立ちます。
Compact Blockによるメリットを得るのは?
-
トランザクションを中継したいがインターネット帯域幅が制限されているフルノードユーザー。ブロックをピアに中継しながら、可能な限り最大帯域幅を節約したい場合は、Bitcoin Core v0.12以降で使用可能な
blocksonlyモードが既にあります。blocksonlyモードはトランザクションがブロックに含まれている場合にのみトランザクションを受け取るため、余計なトランザクションオーバーヘッドはありません。 -
ネットワーク全体。P2Pネットワークでのブロック伝播時間を短縮すると、ベースラインの中継セキュリティマージンが向上し、より健全なネットワークが作成されます。
Compact Block伝播のコーディング、テスト、レビューおよび展開のタイムラインは?
Compact Blockの最初のバージョンにはBIP152が割り当てられ、実装が進められ、開発者コミュニティにより活発にテストされています。
- BIP152: https://github.com/bitcoin/bips/blob/master/bip-0152.mediawiki
- 参照実装: https://github.com/bitcoin/bitcoin/pull/8068
これを更に速いP2Pリレーに対応させることができますか?
Compact Block方式に対するさらなる改良を行うことができます。これらはRN-NGに関連しており、2つあります:
-
まず、ブロック情報のTCP伝送をUDP伝送に置き換えます。
-
続いて、前方誤り訂正(FEC)符号を使用してドロップパケットを処理し、欠落したトランザクションデータを先取りして送信します。
UDT伝送では、断続的なドロップパケットを気にせずに経路が許す限り速くデータをサーバから送信し、クライアントで整理できます。クライアントができるだけ速くブロックを構築するためには、パケットを順番通りに処理しない方がいいのですが、TCPはこれを許可しません。
ドロップパケットを処理し、複数のサーバから非冗長ブロックデータを受信するため、FEC符号が採用されます。FEC符号は元のデータを冗長符号に変換する方法で、必要なデータが元のデータサイズよりわずかに大きいだけで、一定の割合のパケットが宛先に到着する限り、無損失伝送を可能にします。
これにより、ノードはブロックを受信するとすぐにブロックの送信を開始でき、受信者は複数のピアから同時にストリーミングされたブロックを再構築できます。この作業は全て既に完了したCompact Blockの作業をベースにしています。これは中期的な拡張であり、開発は進行中です。
この発想は新しいもの?
ブロックをより効率的に送信するためにBloom Filterを使う(BIP37のfilteredblocksで使用されるものなど)というアイディアは、数年前に提案されました。2013年にPieter Wuille (sipa)によって実装もされましたが、オーバーヘッドが原因で伝送が遅くなることが分かりました。
[#bitcoin-dev, public log (excerpts)]
[2013-12-27]
09:12 < sipa> TD: i'm working on bip37-based block propagation
[...]
10:27 < BlueMatt> sipa: bip37 doesnt really make sense for block download, no? why do you want the filtered merkle tree instead of just the hash list (since you know you want all txn anyway)
[...]
15:14 < sipa> BlueMatt: the overhead of bip37 for full match is something like 1 bit per transaction, plus maybe 20 bytes per block or so
15:14 < sipa> over just sending the txid list
[2013-12-28]
00:11 < sipa> BlueMatt: i have a ~working bip37 block download branch, but it's buggy and seems to miss blocks and is very slow
00:15 < sipa> BlueMatt: haven't investigated, but my guess is transactions that a peer assumes we have and doesn't send again
00:15 < sipa> while they already have expired from our relay pool
[...]
00:17 < sipa> if we need to ask for missing transactions, there is an extra roundtrip, which makes it likely slower than full block download for many connections
00:18 < BlueMatt> you also cant request missing txn since they are no longer in mempool [...]
00:21 < gmaxwell> sounds like we really do need a protocol extension for this.
[...] 00:23 < sipa> gmaxwell: i don't see how to do it without extra roundtrip
00:23 < BlueMatt> send a list of txn in your mempool (or bloom filter over them or whatever)!抜粋で述べたように、トランザクションを要求するために個々のトランザクションハッシュの送信と同様、ブロック内の個々のトランザクションの送信をサポートするようプロトコルを拡張することで、Compact Block方式をはるかに単純化し、DoS耐性があり、より効率的にすることができます。
さらに詳しい情報源
- https://people.xiph.org/~greg/efficient.block.xfer.txt
- https://people.xiph.org/~greg/lowlatency.block.xfer.txt
- https://people.xiph.org/~greg/weakblocks.txt
- https://people.xiph.org/~greg/mempool_sync_relay.txt
- https://en.bitcoin.it/wiki/User:Gmaxwell/block_network_coding
- http://diyhpl.us/~bryan/irc/bitcoin/block-propagation-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/weak-blocks-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/propagation-links.2016-05-09.txt